12月26日,《人工智能系列读书班》活动照常进行,何川博士主持了“聚类”算法的讨论会,首先介绍了聚类算法的任务、性能度量、距离计算,然后重点介绍了原型聚类中的Kmeans均值算法、学习向量量化LVQ以及高斯混合聚类GMM,最后介绍了密度聚类DBSCAN、层次聚类AGNES等:

图1 何川博士主持聚类算法讨论会
活动中,何川博士分享了几个聚类算法在多个数据集上的运行结果,并分析了各自的优缺点:

图2 多个聚类算法的演示界面
原型聚类中,Kmeans简单但受制于预先设定聚类数,GMM的聚类效果相对比较好,但聚类数的预先设定将影响实验结果:
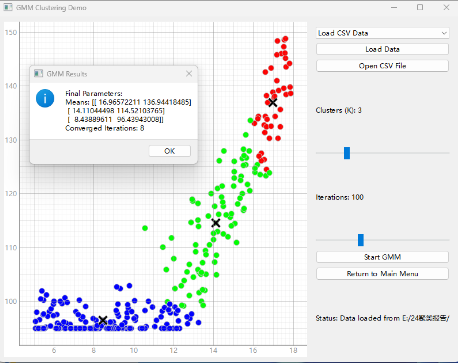
图3 GMM聚类实验结果图
密度聚类,不需要预先指定聚类数,但要预先指定簇的最小点数和半径,如果这两个参数设置不好,容易使得聚类结果的局部最优化,达不到全局最优化,如下:

图4 DBSCAN聚类实验结果图
在自由讨论环节,大家讨论了集中聚类算法的优缺点,在垂直领域已知数据分布的情况下,Kmeans简单有效;GMM采用概率模型表达聚类原型,与深度学习架构可以建立级联关系;同时讨论了密度聚类DBSCAN与原型聚类GMM是否可以结合的问题。
何川博士还分享了最近几年聚类算法的改进的主要工作,包括对比聚类、基于粒球的快速DBSCAN聚类、基于图滤波的子空间聚类算法、混合遗传-模糊蚁群优化算法的自动k均值聚类方法、粒球计算的流形聚类算法等。
最后,沈来信教授分享了GMM在语音识别、图像分割等领域的聚类应用:

图5 GMM用于图像分割
(会议总结:沈来信)